If you are interested to learn about the MySQL Ranking functions
A window function in MySQL used to do a calculation across a set of rows that are related to the current row. The current row is that row for which function evaluation occurs. Window functions perform a calculation similar to a calculation done by using the aggregate functions. But, unlike aggregate functions that perform operations on an entire table, window functions do not produce a result to be grouped into one row. It means window functions perform operations on a set of rows and produces an aggregated value for each row. Therefore each row maintains the unique identities.
The window functions are the new feature introduced in the release of MySQL version 8 that improves the execution performance of queries. These functions allow us to solve the query related problem more efficiently.
Syntax
The following are the basic syntax for using a window function:
window_function_name(expression)
OVER (
[partition_defintion]
[order_definition]
[frame_definition]
)In the syntax, it can be seen that we have first specified the name of the window functions, which is followed by an expression. Then, we specify the OVER clause that contains three expressions that are partition_definition, order_definition, and frame_definition. It makes sure that an OVER clause always has an opening and closing parentheses, even it does not have any expression. Let us see the syntax of each expression used in the OVER clause:
Does MySQL support window functions?
MySQL supports window functions that, for each row from a query, perform a calculation using rows related to that row. The following sections discuss how to use window functions, including descriptions of the OVER and WINDOW clauses.
How does Window Functions work in MySQL?
The window functions work close to aggregate functions. Let’s compare the operations of both functions.
Scenario: segregate the total marks of each student in the class
Code:
<code>SELECT student_name, SUM (marks)<br>from students<br>GROUP BY student_name;</code>
Output:
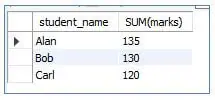
Here we used aggregate function SUM () to get total and we saw the number of rows is reduced.
Code:
using window function:
<code>SELECT student_name, subject, marks,<br>SUM (marks) OVER () AS Total_marks,<br>SUM (marks) OVER (PARTITION BY student_name) AS perhead_total<br>From students<br>ORDER BY subject;</code>
Analyzing the query: The total_marks column is derived as a sum of marks of all students in all subjects, whereas the column perhead_total is, to sum up, the marks per student for all three subjects.
Output:
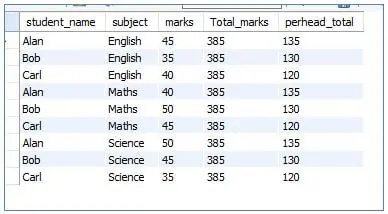
A window function can be used only within a SELECT query, and an OVER() clause is mandatory. The OVER() clause can either be left blank or can hold clauses like PARTITION BY, ORDER BY, etc.Almost all aggregate functions that allow an OVER() clause and certain non-aggressive functions can be used as window functions, with OVER() clause mandatory.
Partition Clause
This clause is used to divide or breaks the rows into partitions, and the partition boundary separates these partitions. The window function operates on each partition, and when it crosses the partition boundary, it will be initialized again. The syntax of this clause is given below:
PARTITION BY <expression>[{,<expression>...}] In the partition clause, we can define one or more expressions that are separated by commas.
ORDER BY Clause
This clause is used to specify the order of the rows within a partition. The following are the syntax of ORDER BY clause:
ORDER BY <expression> [ASC|DESC], [{,<expression>...}] We can also use it to order the rows within a partition on multiple keys where each key specified by an expression. This clause can also define one or more expressions that are separated by commas. Although the ORDER BY clause can work with all window functions, it is recommended to use it with order-sensitive window function.
Frame Clause
A frame is the subset of the current partition in window functions. So we use frame clause to define a subset of the current partition. The syntax of creating a subset of the current partition using frame clause is as follows:
frame_unit {<frame_start>|<frame_between>} We can use the current row to define a Frame that allows moving within a partition with respect to the position of the current row. In the syntax, the frame_unit that can be ROWS or RANGE is responsible for defining the type of relationship between the frame row and the current row. If the frame_unit is ROWS, then the offset of the frame rows and the current row is row number. While if the frame_unit is RANGE, then the offset is row values. The frame_start and frame_between expressions are used to specify the frame boundary. The frame_start expression has three things:
UNBOUNDED PRECEDING: Here, the frame starts from the first row of a current partition.
N PRECEDING: Here, N is a literal number or an expression that evaluates in numbers. It is the number of rows before the first current row.
CURRENT ROW: It specifies the row of the recent calculation
The frame_between expression can be written as:
BETWEEN frame_boundary_1 AND frame_boundary_2
The above expression can have one of the following things:
frame_start: We have already explained it previously.
UNBOUNDED FOLLOWING: It specifies the end of the frame at the final row in the partition.
N FOLLOWING: It is the physical N of rows after the first current row.
If the frame_definition is not specified in the OVER clause, then by default uses the below frame:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
Window Function Concept
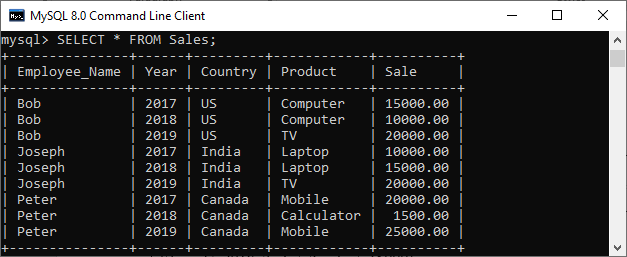
In this section, we are going to see how we can use the window. so let us first create a table named “Sales” using the following statement:
CREATE TABLE Sales(
Employee_Name VARCHAR(45) NOT NULL,
Year INT NOT NULL,
Country VARCHAR(45) NOT NULL,
Product VARCHAR(45) NOT NULL,
Sale DECIMAL(12,2) NOT NULL,
PRIMARY KEY(Employee_Name, Year)
); Next, we have to add records into the table using as below:
INSERT INTO Sales(Employee_Name, Year, Country, Product, Sale)
VALUES('Joseph', 2017, 'India', 'Laptop', 10000),
('Joseph', 2018, 'India', 'Laptop', 15000),
('Joseph', 2019, 'India', 'TV', 20000),
('Bob', 2017, 'US', 'Computer', 15000),
('Bob', 2018, 'US', 'Computer', 10000),
('Bob', 2019, 'US', 'TV', 20000),
('Peter', 2017, 'Canada', 'Mobile', 20000),
('Peter', 2018, 'Canada', 'Calculator', 1500),
('Peter', 2019, 'Canada', 'Mobile', 25000); To verify the records into a table, use the SELECT statement:
After execution, we can see that the records are added successfully into the table.
To understand window function, let us first see how an aggregate function works in MySQL. The aggregate function evaluates multiple rows and produces the result set into one row. So, execute the below statement that uses the aggregate function “SUM” and returns the total sales of all employees in the given year:
mysql> SELECT SUM(sale) AS Total_Sales FROM Sales;
Output
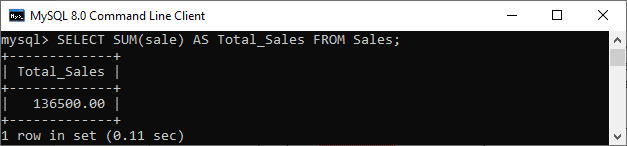
Again, we use the “SUM” function with the GROUP BY clause that works on the subset of rows. So, execute the below statement that returns the total sales of all products group by particular years:
mysql> SELECT Year, Product, SUM(Sale) AS Total_Sales FROM Sales GROUP BY Year ORDER BY Product;
Output
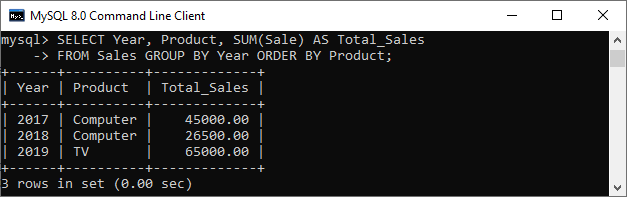
In both examples, we can see that an aggregate function reduces the number of rows into a single row after the execution of the query.
Similar to aggregate function, window function also works with a subset of rows, but it does not reduce the result set into a single row. It means window functions perform operations on a set of rows and produces an aggregated value for each row. For example, execute the following statement that returns sales for each product along with total sales of the products by the given year:
mysql> SELECT Year, Product, Sale, SUM(Sale) OVER(PARTITION BY Year) AS Total_Sales FROM Sales;
Output
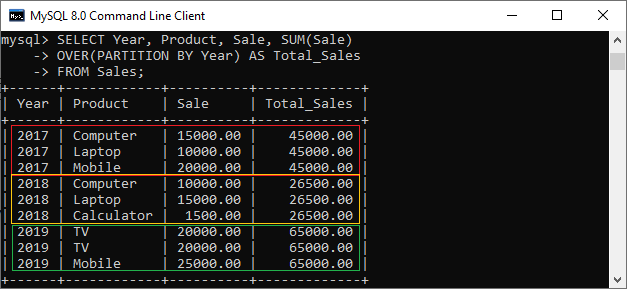
In the above example, we can see that the window operation uses an OVER clause, which is responsible for partitioning the query rows into groups that processed by the window function. Here, the OVER clause partitions rows by year and produces a sum on every partition. After successful calculation, it produces this sum corresponding to each partitioning row.
Types of Window Function
We can categorize the window functions mainly in three types that are given below:
Aggregate Functions
It is a function that operates on multiple rows and produces the result in a single row. Some of the important aggregate functions are:
COUNT, SUM, AVG, MIN, MAX, and many more.
Ranking Functions
It is a function that allows us to rank each row of a partition in a given table. Some of the important ranking functions are:
RANK, DENSE_RANK, PERCENT_RANK, ROW_NUMBER, CUME_DIST, etc.
Analytical Functions
It is a function, which is locally represented by a power series. Some of the important analytical functions are:
NTILE, LEAD, LAG, NTH, FIRST_VALUE, LAST_VALUE, etc.
Example of Analytical Function
Here, we are going to use the NTILE window function. This function takes an integer value as an argument that divides the group into a number of integer values. For example, if we use NTILE(4), then it divides the total records into four groups. When the total record is odd, it adds the odd records in the first row. The following query explains it more clearly.
SELECT Year, Product, Sale, NTile(4) OVER() AS Total_Sales FROM Sales;
Output
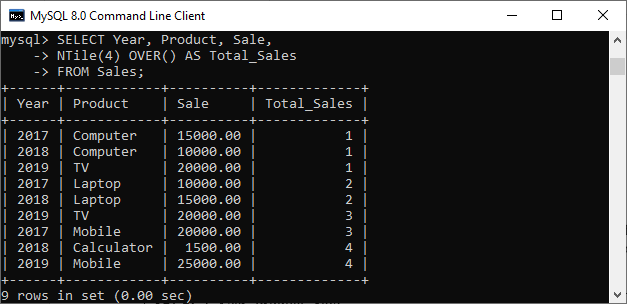
In the above output, we can see that we have a total of 9 rows. So, the NTILE function divides it into four rows, and one extra row will be added into the first row. Let us see another example using the “LEAD” function. This function is used to query more than one row in a table without joining the table itself. It means we can access the data of the next row from the current row. It returns the output from the next row. Execute the following statement to understand it more clearly:
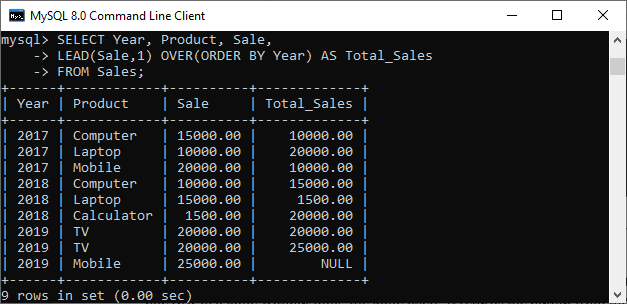
SELECT Year, Product, Sale, LEAD(Sale,1) OVER(ORDER BY Year) AS Total_Sales FROM Sales;
Output
1. ROW NUMBER ( )
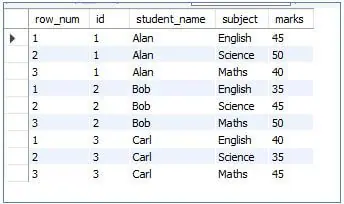
This function is used to insert row numbers to each row. As a window function, it will add rows to the small groups of result sets and will have the following syntax:
Code:
<code>SELECT<br>ROW_NUMBER() OVER (PARTITION BY student_name) AS row_num, <br>id,<br>student_name, <br>subject, <br>marks<br>FROM students<br>ORDER BY student_name; </code>
Output:
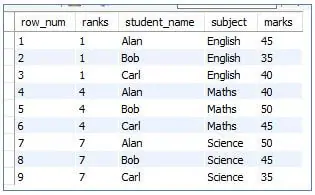
2. RANK()
This function will provide every row with rank but it is not always a consecutive number like Row_number().
Code:
<code>SELECT<br>ROW_NUMBER() OVER (order by subject) as row_num,<br>RANK () OVER (ORDER BY subject) as ranks, <br>student_name, <br>subject, <br>marks<br>FROM students; </code>
Output:
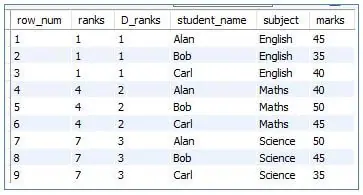
3. DENSE RANK ()
This function is similar to the RANK() function except for the fact that even when divided into smaller groups of the total result set, the DENSE_RANK() function will assign consecutive rank numbers for each group.
Code:
<code>SELECT<br>ROW_NUMBER() OVER (order by subject) as row_num, <br>RANK () OVER (ORDER BY subject) as ranks, <br>DENSE_RANK () OVER (ORDER BY subject) as D_ranks, <br>student_name,<br>subject,<br>marks<br>FROM students;</code>
Output:
4. PERCENT_RANK()
This function calculates the percentile of a row within the small result set and will return a value ranging from 0 to 1 for every row. Also, note that the function will return 0 for the first-row set.
Code:
<code>SELECT<br>ROW_NUMBER() OVER (order by subject) as row_num, <br>PERCENT_RANK () over (order by subject) as percentile_rank, <br>RANK () OVER (ORDER BY subject) as ranks, <br>DENSE_RANK () OVER (ORDER BY subject) as D_ranks,<br>student_name, <br>subject,<br>marks<br>FROM students;</code>
Output:
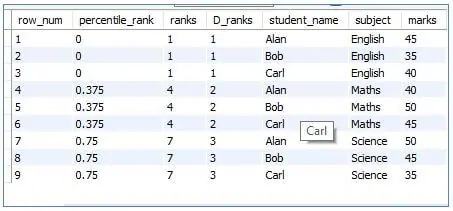
5. CUME_DIST()
This will return the Cumulative Distribution of a value over a set of values in the result set. The value returned will be within 0 to 1 and any repetition in the column value will end up in the same cumulative distribution.
Code:
<code>SELECT<br>ROW_NUMBER() OVER (order by marks) as row_num, <br>RANK () OVER (ORDER BY marks) as ranks, <br>CUME_DIST () over (order by marks) as cume_distribution,<br>student_name, <br>marks<br>FROM marklist;</code>
Output:
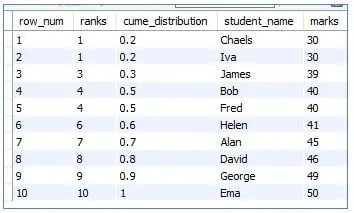
6. NTILE()
This helps to split the result set rows into a specified number of groups based upon the partition_by and order_by clauses provided.
Code:
<code>SELECT<br>ROW_NUMBER() OVER (order by marks) as row_num, <br>NTILE (4) over (order by marks) as group_number, <br>student_name, <br>marks<br>FROM marklist; </code>
Output:
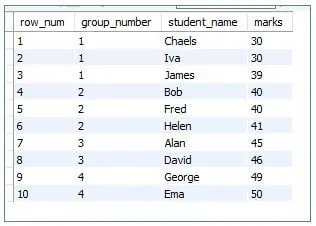
7. LAG()
LAG() is a window function that returns the value to the previous rows in a sorted and partitioned result set.
Code:
<code>SELECT<br>employee, <br>year, <br>sales, <br>LAG (sales, 1) OVER (PARTITION BY employee ORDER BY year) prev_year_sales<br>FROM sales;</code>
Output:
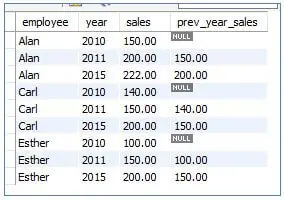
8. LEAD()
This function does the exact opposite operation of lag() function. Lead() function will return the values ahead, in the partitioned and sorted result set.
Code:
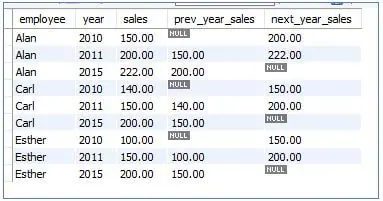
<code>SELECT<br>employee, <br>year, <br>sales, <br>LAG (sales, 1) OVER (PARTITION BY employee ORDER BY year) prev_year_sales, <br>LEAD (sales, 1) OVER (PARTITION BY employee ORDER BY year) next_year_sales<br>FROM sales;</code>
Output:
9. FIRST VALUE()
This window function returns the first row among a partitioned sorted result set.
Code:
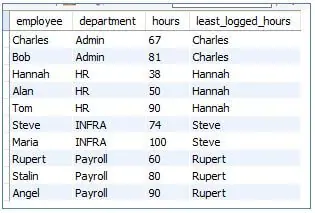
<code>SELECT<br>employee, <br>department, <br>hours, <br>FIRST_VALUE (employee) OVER (PARTITION BY department ORDER BY hours) AS least_logged_hours<br>FROMloggedhours; </code>
Output:
10. LAST VALUE()
This window function returns the first row among a partitioned sorted result set. The syntax is as follow:
Code:
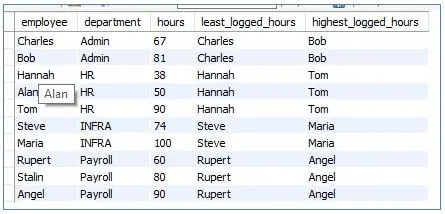
<code>SELECT<br>employee,<br>department, <br>hours,<br>FIRST_VALUE (employee) OVER (PARTITION BY department ORDER BY hours) AS least_logged_hours,<br>LAST_VALUE (employee) OVER (PARTITION BY department ORDER BY hours <br>RANGE BETWEEN UNBOUNDED PRECEEDING AND<br>UNBOUNDED FOLLOWING) AS highest_logged_hours<br>FROM loggedhours;</code>
Output:
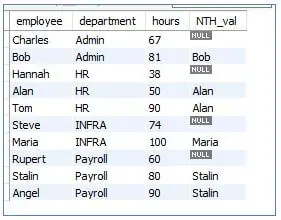
11. NTH VALUE ()
The window function NTH_VALUE returns the Nth row among a partitioned sorted result set.
Code:
<code>SELECT<br>employee, <br>department, <br>hours, <br>NTH_VALUE (employee, 2) <br>FROM FIRST<br>OVER ( PARTITION BY department ORDER BY hours) as NTH_val<br>FROM loggedhours;</code>
Output: