
If You are interested to learn about the GraphQL Environment setup
GraphQL architecture consists of three main components: the client, the server, and the schema.
- Client: The client is the application that sends GraphQL queries to the server. It could be a web, mobile or desktop application.
- Server: The server receives the queries from the client, interprets them, and responds with the requested data. The server can be built using any server-side technology that supports GraphQL.
- Schema: The schema is the contract between the client and the server. It defines the types of data that can be queried, the relationships between them, and the operations that can be performed on that data. The schema is defined using the GraphQL schema language.
In the GraphQL architecture, the client has complete control over the data it receives from the server. Instead of the server defining a fixed set of endpoints that return pre-determined data, the client specifies exactly what data it needs by constructing a GraphQL query. The server then responds with only the data that was requested, reducing unnecessary network traffic and improving performance.
Another key aspect of the GraphQL architecture is the use of resolvers. Resolvers are functions that determine how to fetch the data for a particular field in the schema. They can fetch data from a database, call external APIs, or perform any other necessary operations to retrieve the requested data.
GraphQL Server can be deployed by using any of the three methods listed below −
- GraphQL server with connected database
- GraphQL server that integrates existing systems
- Hybrid approach
GraphQL Server with Connected Database
This architecture has a GraphQL Server with an integrated database and can often be used with new projects. On the receipt of a Query, the server reads the request payload and fetches data from the database. This is called resolving the query. The response returned to the client adheres to the format specified in the official GraphQL specification.
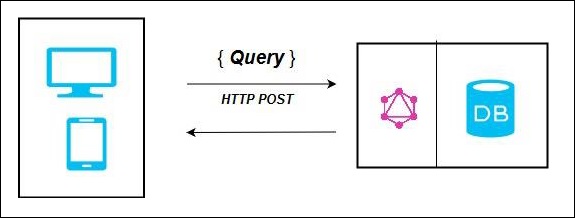
In the above diagram, GraphQL server and the database are integrated on a single node. The client (desktop/mobile) communicates with GraphQL server over HTTP. The server processes the request, fetches data from the database and returns it to the client.
GraphQL Server Integrating Existing Systems
This approach is helpful for companies which have legacy infrastructure and different APIs. GraphQL can be used to unify microservices, legacy infrastructure and third-party APIs in the existing system.
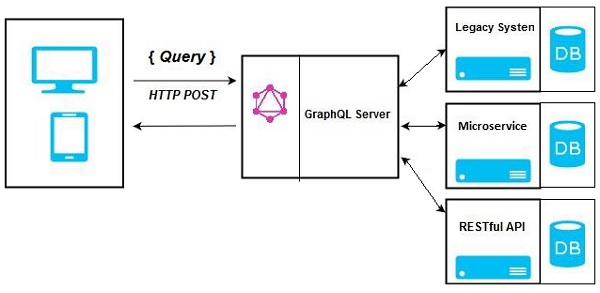
In the above diagram, a GraphQL API acts as an interface between the client and the existing systems. Client applications communicate with the GraphQL server which in turn resolves the query.
Hybrid Approach
Finally, we can combine the above two approaches and build a GraphQL server. In this architecture, the GraphQL server will resolve any request that is received. It will either retrieve data from connected database or from the integrated API’s. This is represented in the below figure −
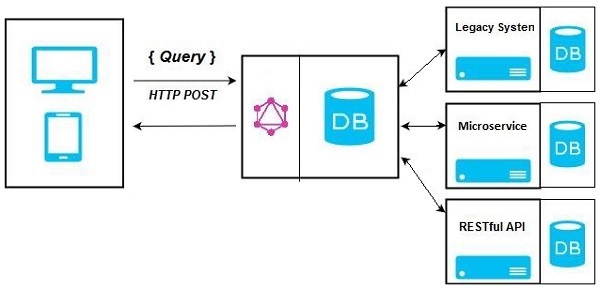
Types of Architecture of GraphQL
There are several types of architecture that can be used to implement GraphQL:
- Single-server Architecture: This architecture involves a single server handling both the GraphQL API and the data storage layer. It is simple to implement and can be effective for small projects or proof-of-concept applications.
- Federation Architecture: In this architecture, multiple GraphQL services are combined to form a single, unified API. Each service handles a specific domain or data type, and the federation layer coordinates communication between them. This approach can be useful for large-scale applications with multiple teams or data sources.
- Gateway Architecture: In a gateway architecture, a single GraphQL server acts as a gateway to other APIs and services. The gateway provides a unified interface to the client, and routes requests to the appropriate backend service. This approach can be effective for integrating multiple APIs and services into a single application.
- Hybrid Architecture: A hybrid architecture combines elements of multiple architectures to create a solution that meets the specific needs of the application. For example, a GraphQL API may use a single-server architecture for certain data types, while using a federation architecture for others.
Ultimately, the choice of architecture will depend on the specific requirements of the application, including factors such as scalability, maintainability, and complexity. It’s important to carefully consider your needs and choose an architecture that will support your goals both now and in the future.
Advantages of GraphQL Architecture
GraphQL offers several advantages over traditional REST-based architectures, including:
- Reduced network overhead: In GraphQL, clients can request only the data they need, which reduces the amount of data transferred over the network. This helps to improve performance and reduce network latency.
- Increased flexibility: With GraphQL, clients can specify exactly what data they need, and the server will respond with only that data. This allows clients to be more flexible and adapt to changing requirements.
- Improved developer experience: GraphQL offers a type system that makes it easier for developers to reason about the data being requested and returned. This helps to improve the developer experience and reduce the risk of errors.
- Better data validation: With GraphQL, the server can validate the incoming data and ensure that it meets the expected format before processing it. This helps to reduce the risk of errors and improve the overall data quality.
- Simplified backend: With GraphQL, the backend can be simplified, as it no longer needs to support multiple endpoints for different client applications. This makes it easier to maintain and scale the backend.
- Easier versioning: With GraphQL, changes to the API can be made without breaking existing clients, as clients can specify exactly what data they need. This makes it easier to evolve the API over time without causing disruptions to existing clients.

