
If you are interested to learn about the MySQL COALESCE() Function
MySQL is a database application that stores data in tables in the form of rows and columns. This database application can store duplicate records in the table, which can impact the performance of the database in MySQL. However, data duplication occurs due to various reasons and finding the duplicate values in the table is an important task while working with a database in MySQL. Generally, it is a good idea to always use unique constraints on a table to store data that prevent having duplicate rows. However, sometimes working with a database, we can find many duplicate rows due to human error, uncleaned data from external sources, or a bug in the application. In this article, we are going to learn how we can find duplicate values in a database.
Let us understand it with the help of an example. First, we will create a table named “student_contacts” using the following statement:
CREATE TABLE student_contacts (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
state VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
); Next, we will fill the record into the table using as follows:
INSERT INTO student_contacts (name, state, email)
VALUES ('Carine', 'Texas', 'carine@javatpoint.com'),
('Carine', 'Texas', 'carine@javatpoint.com'),
('Peter', 'New York', 'peter@javatpoint.com'),
('Janine ', 'Florida', 'janine@javatpoint.com'),
('Janine ', 'Florida', 'janine@javatpoint.com'),
('Jonas ', 'Atlanta', 'jonas@javatpoint.com'),
('Jean', 'California', 'jean@javatpoint.com'),
('Jean', 'California', 'jean@javatpoint.com'),
('Mark ', 'Florida', 'mark@javatpoint.com'),
('Roland', 'Alabama', 'roland@javatpoint.com'),
('Roland', 'Alabama', 'roland@javatpoint.com'),
('Julie', 'Texas', 'julie@javatpoint.com'),
('Shane', 'New York', 'shane@javatpoint.com'),
('Susan', 'Arizona', 'susan@javatpoint.com'),
('Susan', 'Arizona', 'susan@javatpoint.com'); Execute the SELECT statement to verify the record:
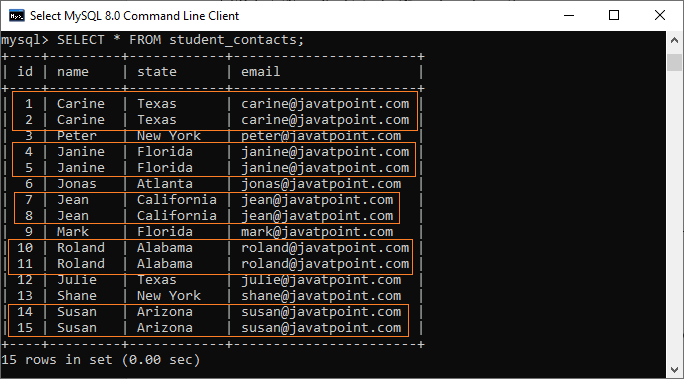
In this table, we can see that there are various rows available with duplicate values. Let’s learn how we can find them using the query.
Find Duplicate Data in a Single Column
We can find the duplicate entries in a table using the below steps:
- First, we will use the GROUP BY clause for grouping all rows based on the desired column. The desired column is the column based on which we will check duplicate records.
- Second, we will use the COUNT() function in the HAVING clause that checks the group, which has more than one element.
The following syntax explains the above steps:
SELECT column, COUNT(column) FROM table_name GROUP BY column HAVING COUNT(column) > 1;
With the help of the above syntax, we can use the below statement to find rows that have duplicate names in the student_contacts table:
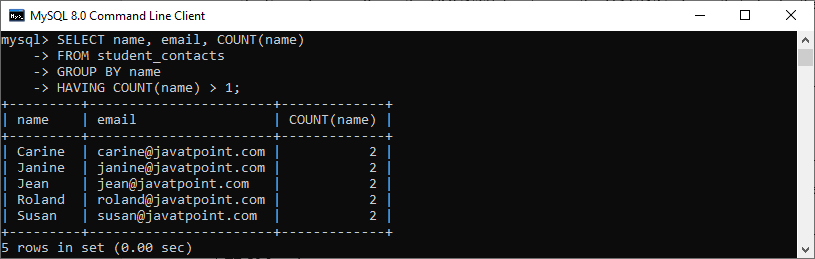
SELECT name, email, COUNT(name) FROM student_contacts GROUP BY name HAVING COUNT(name) > 1;
After executing the above statements, we will get the below output that shows the duplicates names and emails:
Find Duplicate Data in Multiple Columns
Sometimes we need to find duplicate values based on multiple columns. In that case, we can use the syntax as follows:
SELECT
column1, COUNT(column1),
column2, COUNT(column2),……
FROM table_name
GROUP BY column1, column2, .......
HAVING
(COUNT(column1) > 1) AND
(COUNT(column2) > 1) AND ….... We should note that while finding duplicates in multiple columns, the rows are duplicated only when the combination of columns is duplicated. Therefore, we need to use the AND operator .
For example, if we want to find rows in the student_contacts table that contains duplicate values in name, state, and email columns, the following query can be used:
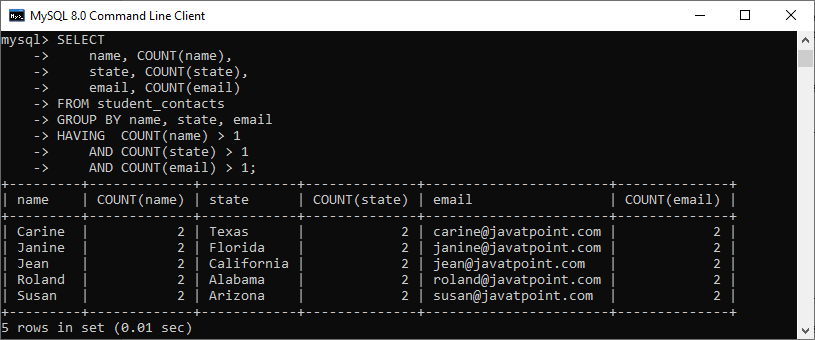
SELECT
name, COUNT(name),
state, COUNT(state),
email, COUNT(email)
FROM student_contacts
GROUP BY name, state, email
HAVING COUNT(name) > 1
AND COUNT(state) > 1
AND COUNT(email) > 1; After executing the above statements, we will get the below output that shows the duplicates name, state, and emails columns:
How to select nth Highest Record in MySQL
In this section, we are going to learn how we can select the nth highest record in a database table with the help of various techniques. We can get the maximum (highest) or minimum (lowest) record in the database table very easily by using the MAX() or MIN() function. But suppose we want to get the nth highest record from the table (for example, get the second-most expensive salary from the employee table). In that case, there is no function available to find it quickly, which makes it complicated.
By performing the following steps, we can select the nth highest record in a MySQL database table:
1. The first step is to sort the desired column in ascending order to get the n highest records, which is the last record in the resultant output. See the below query:
SELECT * FROM table_name ORDER BY colm_name ASC LIMIT N;
2. After that, we need to sort the resultant output in descending order and get the first record.
SELECT * FROM ( SELECT * FROM table_name ORDER BY colm_name ASC LIMIT N) AS temp_table ORDER BY colm_name DESC LIMIT 1;
The above query can also be rewritten by using the LIMIT clause that constrains the number of rows in the resultant output as follows:
SELECT * FROM table_name ORDER BY colm_name DESC LIMIT n - 1, 1;
This query will return the first row after the n-1 rows that should be the nth highest record.
How do you select the highest nth value in SQL?
Using this function we can find the nth highest value using the following query.
- DECLARE @nthHighest INT = 2. …
- DECLARE @nthHighest INT = 2.
- ;WITH CTE(EmpId,Empcode,Name,Salary,EmpRank)
- SELECT EmpId,Empcode,Name,Salary,
- DENSE_RANK() OVER(ORDER BY Salary DESC) AS EmpRank.
- SELECT * FROM CTE WHERE EmpRank = @nthHighest.
How do you find the nth highest from a table?
select * from( select ename, sal, dense_rank() over(order by sal desc)r from Employee) where r=&n; To find to the 2nd highest sal set n = 2 To find 3rd highest sal set n = 3 and so on. Output : DENSE_RANK : DENSE_RANK computes the rank of a row in an ordered group of rows and returns the rank as a NUMBER.
Example:
Let us understand how to get the nth highest record from the table with the help of an example. First, we will create an Employee table using the below query:
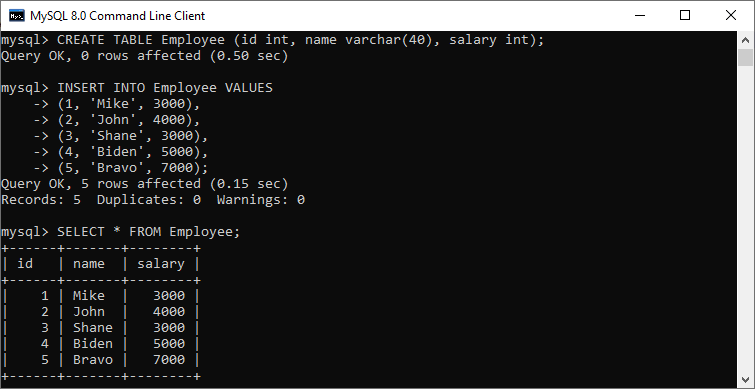
CREATE TABLE Employee (id int, name varchar(40), salary int);
Next, insert records using the below query:
INSERT INTO Employee VALUES (1, 'Mike', 3000), (2, 'John', 4000), (3, 'Shane', 3000), (4, 'Biden', 5000), (5, 'Bravo', 7000);
Execute the SELECT statement to verify the record:
Suppose we want to get the second highest salary of an employee (n = 2) in the Employee table; we can use the below statement:
mysql> SELECT name, salary FROM Employee ORDER BY salary DESC LIMIT 1, 1;
We will see the output as follows:
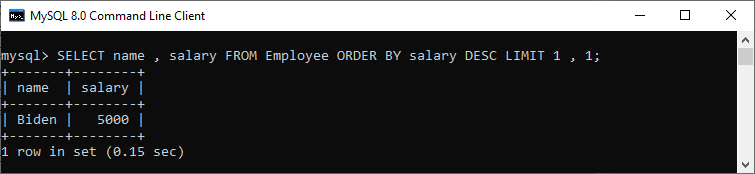
Suppose we want to get the third-highest salary of an employee (n = 3) in the Employee table; we can use the below statement:
mysql> SELECT name, salary FROM Employee ORDER BY salary DESC LIMIT 2, 1;
We will see the output as follows:
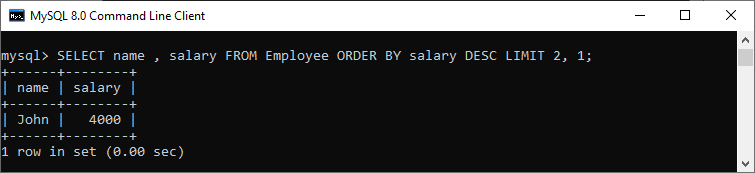
Get the nth highest record using a subquery
We can also get the nth highest record with the help of subquery, which depends upon the main query and processed for every record returned by the main query. This technique is rarely used because of its slow performance/execution speed. See the below query that returns nth highest record using the subquery:
SELECT name, salary FROM Employee AS emp1 WHERE N-1 = (SELECT COUNT(DISTINCT salary) FROM Employee emp2 WHERE emp2.salary > emp1.salary)
See the below query that returns the second highest salary from the employee table using the subquery:
SELECT name, salary FROM Employee AS emp1 WHERE 2-1 = (SELECT COUNT(DISTINCT salary) FROM Employee AS emp2 WHERE emp2.salary > emp1.salary);
We will get the same output returned by the previous query:
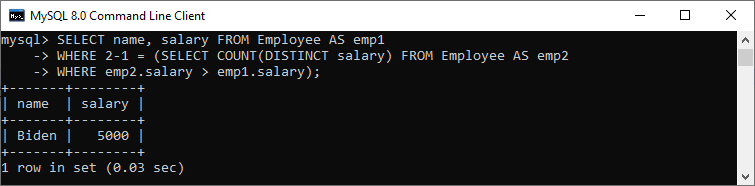
How do you find the nth highest from a table?
select * from( select ename, sal, dense_rank() over(order by sal desc)r from Employee) where r=&n; To find to the 2nd highest sal set n = 2 To find 3rd highest sal set n = 3 and so on. Output : DENSE_RANK : DENSE_RANK computes the rank of a row in an ordered group of rows and returns the rank as a NUMBER. if you want to get the second most expensive product (n = 2) in the products table, you use the following query:
<code>SELECT
productCode, productName, buyPrice
FROM
products
ORDER BY buyPrice DESC
LIMIT 1 , 1;</code><small>Code language: SQL (Structured Query Language) (sql)</small>Output
Here is the result:

The second technique to get the nth highest record is using MySQL subquery:
<code>SELECT * FROM table_name AS a WHERE n - 1 = ( SELECT COUNT(primary_key_column) FROM products b WHERE b.column_name > a. column_name)</code><small>Code language: SQL (Structured Query Language) (sql)</small>
You can achieve the same result using the first technique to get the second most expensive product as the following query:
<code>SELECT
productCode, productName, buyPrice
FROM
products a
WHERE
1 = (SELECT
COUNT(productCode)
FROM
products b
WHERE
b.buyPrice > a.buyPrice);</code><small>Code language: SQL (Structured Query Language) (sql)</small>
