
If you are interested to learn about the DevOps Introduction
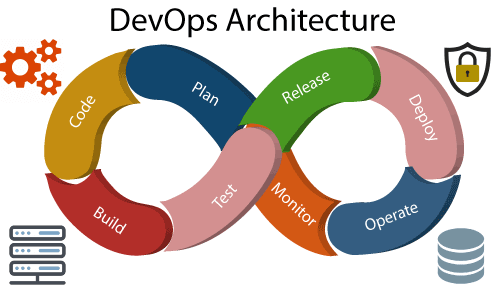
Development and operations both play essential roles in order to deliver applications. The deployment comprises analyzing the requirements, designing, developing, and testing of the software components or frameworks.
The operation consists of the administrative processes, services, and support for the software. When both the development and operations are combined with collaborating, then the DevOps architecture is the solution to fix the gap between deployment and operation terms; therefore, delivery can be faster.
DevOps architecture is used for the applications hosted on the cloud platform and large distributed applications. Agile Development is used in the DevOps architecture so that integration and delivery can be contiguous. When the development and operations team works separately from each other, then it is time-consuming to design, test, and deploy. And if the terms are not in sync with each other, then it may cause a delay in the delivery. So DevOps enables the teams to change their shortcomings and increases productivity.
Below are the various components that are used in the DevOps architecture:Play Videox
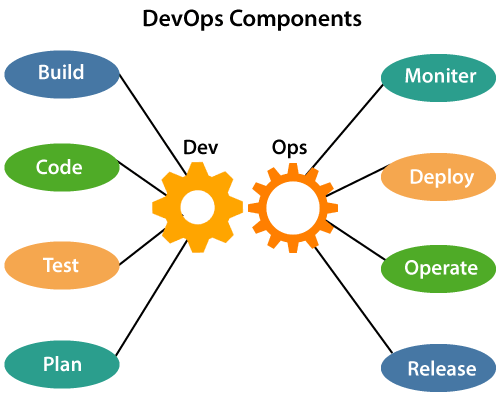
1) Build
Without DevOps, the cost of the consumption of the resources was evaluated based on the pre-defined individual usage with fixed hardware allocation. And with DevOps, the usage of cloud, sharing of resources comes into the picture, and the build is dependent upon the user’s need, which is a mechanism to control the usage of resources or capacity.
2) Code
Many good practices such as Git enables the code to be used, which ensures writing the code for business, helps to track changes, getting notified about the reason behind the difference in the actual and the expected output, and if necessary reverting to the original code developed. The code can be appropriately arranged in files, folders, etc. And they can be reused.
3) Test
The application will be ready for production after testing. In the case of manual testing, it consumes more time in testing and moving the code to the output. The testing can be automated, which decreases the time for testing so that the time to deploy the code to production can be reduced as automating the running of the scripts will remove many manual steps.
4) Plan
DevOps use Agile methodology to plan the development. With the operations and development team in sync, it helps in organizing the work to plan accordingly to increase productivity.
5) Monitor
Continuous monitoring is used to identify any risk of failure. Also, it helps in tracking the system accurately so that the health of the application can be checked. The monitoring becomes more comfortable with services where the log data may get monitored through many third-party tools such as Splunk.
6) Deploy
Many systems can support the scheduler for automated deployment. The cloud management platform enables users to capture accurate insights and view the optimization scenario, analytics on trends by the deployment of dashboards.
7) Operate
DevOps changes the way traditional approach of developing and testing separately. The teams operate in a collaborative way where both the teams actively participate throughout the service lifecycle. The operation team interacts with developers, and they come up with a monitoring plan which serves the IT and business requirements.
8) Release
Deployment to an environment can be done by automation. But when the deployment is made to the production environment, it is done by manual triggering. Many processes involved in release management commonly used to do the deployment in the production environment manually to lessen the impact on the customers.
Ways to improve your architecture
With an architecture that enables small teams of developers to independently implement, test, and deploy code into production safely and quickly, you can increase developer productivity and improve deployment outcomes. A key feature of service-oriented and microservice architectures is that they’re composed of loosely coupled services with bounded contexts. One popular set of patterns for modern web architecture based on these principles is the twelve-factor app.
Randy Shoup observed the following:
“Organizations with these types of service-oriented architectures, such as Google and Amazon, have incredible flexibility and scalability. These organizations have tens of thousands of developers where small teams can still be incredibly productive.”
In many organizations, services are distinctly hard to test and deploy. Rather than re-architecting everything, we recommend an iterative approach to improving the design of your enterprise system. This approach is known as evolutionary architecture. In this method, it’s given that successful products and services will require re-architecting during their lifecycle due to the changing requirements placed on them.
One valuable pattern in this context is the strangler fig application. In this pattern, you iteratively replace a monolithic architecture with a more componentized one by ensuring that new work is done following the principles of a service-oriented architecture. You accept that the new architecture might well delegate to the system it is replacing. Over time, as more and more functionality is performed in the new architecture, the old system is “strangled.”
Product and service architectures continually evolve. There are many ways to decide what should be a new module or service, and the process is iterative. When deciding whether to make a piece of functionality into a service, consider if it has the following traits:
- Implements a single business function or capability.
- Performs its function with minimal interaction with other services.
- Is built, scaled, and deployed independently from other services.
- Interacts with other services by using lightweight communication methods, for example, a message bus or HTTP endpoints.
- Can be implemented with different tools, programming languages, data stores, and so on.
Moving to microservices or a service-oriented architecture also changes many things through the organization as a whole. In his platform rant, Steve Yegge presents several critical lessons learned from moving to a SOA:
- Metrics and monitoring become more important and escalations become more difficult because an issue surfaced in one service could be from a service many service calls away.
- Internal services can produce Denial of Service (DOS) type problems, so quotas and message throttling are important in every service.
- QA and monitoring begin to blend, because monitoring must be comprehensive and must exercise the business logic and data of the service.
- When there are many services, having a service-discovery mechanism becomes important for efficient operation of the system.
- Without a universal standard for running a service in a debuggable environment, debugging issues in other people’s services is much harder.
Case study: Datastore
A tightly coupled architecture can impede everyone’s productivity and ability to safely make changes. In contrast, a loosely coupled architecture promotes productivity and safety with well-defined interfaces that enforce how modules connect with each other. A loosely coupled architecture lets small and productive teams make changes that can be deployed safely and independently. And because each service also has a well-defined API, it enables easier testing of services and the creation of contracts and service level agreements (SLAs) between teams.
Randy Shoup describes this architecture as follows:
“This type of architecture has served Google extremely well, for a service like Gmail, there’s five or six other layers of services underneath it, each very focused on a very specific function. Each service is supported by a small team, who builds it and runs their functionality, with each group potentially making different technology choices. Another example is the Datastore service, which is one of the largest NoSQL services in the world, and yet it is supported by a team of only about eight people, largely because it is based on layers upon layers of dependable services built upon each other.”
This kind of service-oriented architecture allows small teams to work on smaller and simpler units of development that each team can deploy independently, quickly, and safely.
Ways to measure architectural improvement
Whether on a mainframe or in microservices, facilitating the practices required for architectural improvement is essential for improving software delivery performance (increased deployment frequency with reduced lead time for changes, time to restore service, and change failure rate). As your services and products become less tightly coupled, your deployment frequency should increase. When measuring improvement, consider using deployment rate rather than just count, because deployment count naturally increases as services are added. Lastly, you should see a reduction in time to detect and recover from problems and in the time for changes to reach production.
Aside from taking these deployment and service measures, teams that operate more independently demonstrate improvements in job satisfaction and team experimentation, and tend to select different technologies and tools based on their needs.

