
1. What do you know about DevOps?
Your answer must be simple and straightforward. Begin by explaining the growing importance of DevOps in the IT industry. Discuss how such an approach aims to synergize the efforts of the development and operations teams to accelerate the delivery of software products, with a minimal failure rate. Include how DevOps is a value-added practice, where development and operations engineers join hands throughout the product or service lifecycle, right from the design stage to the point of deployment.
2. How is DevOps different from agile methodology?
DevOps is a culture that allows the development and the operations team to work together. This results in continuous development, testing, integration, deployment, and monitoring of the software throughout the lifecycle.
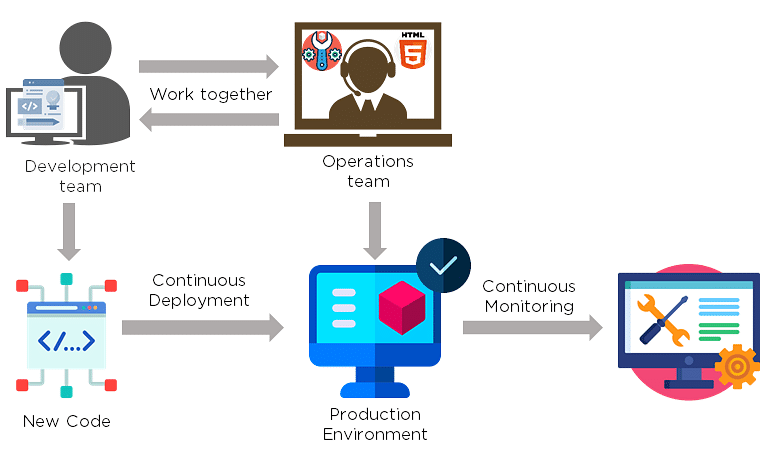
Agile is a software development methodology that focuses on iterative, incremental, small, and rapid releases of software, along with customer feedback. It addresses gaps and conflicts between the customer and developers.

DevOps addresses gaps and conflicts between the Developers and IT Operations.

3. Which are some of the most popular DevOps tools?
The most popular DevOps tools include:
- Selenium
- Puppet
- Chef
- Git
- Jenkins
- Ansible
- Docker
4. What are the different phases in DevOps?
The various phases of the DevOps lifecycle are as follows:
- Plan – Initially, there should be a plan for the type of application that needs to be developed. Getting a rough picture of the development process is always a good idea.
- Code – The application is coded as per the end-user requirements.
- Build – Build the application by integrating various codes formed in the previous steps.
- Test – This is the most crucial step of the application development. Test the application and rebuild, if necessary.
- Integrate – Multiple codes from different programmers are integrated into one.
- Deploy – Code is deployed into a cloud environment for further usage. It is ensured that any new changes do not affect the functioning of a high traffic website.
- Operate – Operations are performed on the code if required.
- Monitor – Application performance is monitored. Changes are made to meet the end-user requirements.
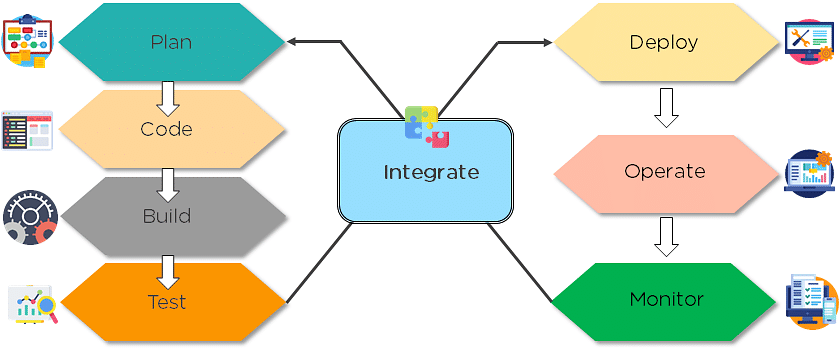
The above figure indicates the DevOps lifecycle.
5. Mention some of the core benefits of DevOps.
The core benefits of DevOps are as follows:
Technical benefits
- Continuous software delivery
- Less complex problems to manage
- Early detection and faster correction of defects
Business benefits
- Faster delivery of features
- Stable operating environments
- Improved communication and collaboration between the teams
6. How will you approach a project that needs to implement DevOps?
The following standard approaches can be used to implement DevOps in a specific project:
Stage 1
An assessment of the existing process and implementation for about two to three weeks to identify areas of improvement so that the team can create a road map for the implementation.
Stage 2
Create a proof of concept (PoC). Once it is accepted and approved, the team can start on the actual implementation and roll-out of the project plan.
Stage 3
The project is now ready for implementing DevOps by using version control/integration/testing/deployment/delivery and monitoring followed step by step. By following the proper steps for version control, integration, testing, deployment, delivery, and monitoring, the project is now ready for DevOps implementation.
7. What is the difference between continuous delivery and continuous deployment?
| Continuous Delivery | Continuous Deployment |
| Ensures code can be safely deployed on to production | Every change that passes the automated tests is deployed to production automatically |
| Ensures business applications and services function as expected | Makes software development and the release process faster and more robust |
| Delivers every change to a production-like environment through rigorous automated testing | There is no explicit approval from a developer and requires a developed culture of monitoring |
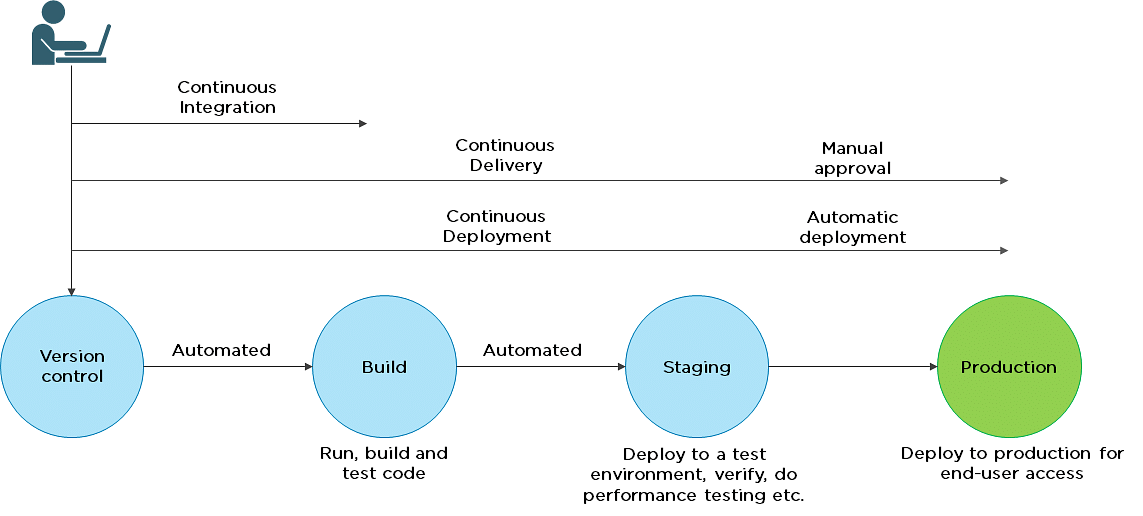
8. What is the role of configuration management in DevOps?
- Enables management of and changes to multiple systems.
- Standardizes resource configurations, which in turn, manage IT infrastructure.
- It helps with the administration and management of multiple servers and maintains the integrity of the entire infrastructure.
9. How does continuous monitoring help you maintain the entire architecture of the system?
Continuous monitoring in DevOps is a process of detecting, identifying, and reporting any faults or threats in the entire infrastructure of the system.
- Ensures that all services, applications, and resources are running on the servers properly.
- Monitors the status of servers and determines if applications are working correctly or not.
- Enables continuous audit, transaction inspection, and controlled monitoring.
10. What is the role of AWS in DevOps?
AWS has the following role in DevOps:
- Flexible services – Provides ready-to-use, flexible services without the need to install or set up the software.
- Built for scale – You can manage a single instance or scale to thousands using AWS services.
- Automation – AWS lets you automate tasks and processes, giving you more time to innovate
- Secure – Using AWS Identity and Access Management (IAM), you can set user permissions and policies.
- Large partner ecosystem – AWS supports a large ecosystem of partners that integrate with and extend AWS services.
11. Name three important DevOps KPIs.
The three important KPIs are as follows:
- Meantime to failure recovery – This is the average time taken to recover from a failure.
- Deployment frequency – The frequency in which the deployment occurs.
- Percentage of failed deployments – The number of times the deployment fails.
12. Explain the term “Infrastructure as Code” (IaC) as it relates to configuration management.
- Writing code to manage configuration, deployment, and automatic provisioning.
- Managing data centers with machine-readable definition files, rather than physical hardware configuration.
- Ensuring all your servers and other infrastructure components are provisioned consistently and effortlessly.
- Administering cloud computing environments, also known as infrastructure as a service (IaaS).
13. How is IaC implemented using AWS?
Start by talking about the age-old mechanisms of writing commands onto script files and testing them in a separate environment before deployment and how this approach is being replaced by IaC. Similar to the codes written for other services, with the help of AWS, IaC allows developers to write, test, and maintain infrastructure entities in a descriptive manner, using formats such as JSON or YAML. This enables easier development and faster deployment of infrastructure changes.
14. Why Has DevOps Gained Prominence over the Last Few Years?
Before talking about the growing popularity of DevOps, discuss the current industry scenario. Begin with some examples of how big players such as Netflix and Facebook are investing in DevOps to automate and accelerate application deployment and how this has helped them grow their business. Using Facebook as an example, you would point to Facebook’s continuous deployment and code ownership models and how these have helped it scale up but ensure the quality of experience at the same time. Hundreds of lines of code are implemented without affecting quality, stability, and security.
Your next use case should be Netflix. This streaming and on-demand video company follow similar practices with fully automated processes and systems. Mention the user base of these two organizations: Facebook has 2 billion users while Netflix streams online content to more than 100 million users worldwide.
These are great examples of how DevOps can help organizations to ensure higher success rates for releases, reduce the lead time between bug fixes, streamline and continuous delivery through automation, and an overall reduction in manpower costs.
15. What are the fundamental differences between DevOps & Agile?
The main differences between Agile and DevOps are summarized below:
| Characteristics | Agile | DevOps |
| Work Scope | Only Agility | Automation needed along with Agility |
| Focus Area | Main priority is Time and deadlines | Quality and Time management are of equal priority |
| Feedback Source | The main source of feedback – customers | The main source of feedback – self (tools used for monitoring) |
| Practices or Processes followed | Practices like Agile Kanban, Scrum, etc., are followed. | Processes and practices like Continuous Development (CD), Continuous Integration (CI), etc., are followed. |
| Development Sprints or Release cycles | Release cycles are usually smaller. | Release cycles are smaller, along with immediate feedback. |
| Agility | Only development agility is present. | Both in operations and development, agility is followed. |
16. What are the anti-patterns of DevOps?
Patterns are common practices that are usually followed by organizations. An anti-pattern is formed when an organization continues to blindly follow a pattern adopted by others but does not work for them. Some of the myths about DevOps include:
- Cannot perform DevOps → Have the wrong people
- DevOps ⇒ Production Management is done by developers
- The solution to all the organization’s problems ⇒ DevOps
- DevOps == Process
- DevOps == Agile
- Cannot perform DevOps → Organization is unique
- A separate group needs to be made for DevOps
17. What are the benefits of using version control?
Here are the benefits of using Version Control:
- All team members are free to work on any file at any time with the Version Control System (VCS). Later on, VCS will allow the team to integrate all of the modifications into a single version.
- The VCS asks to provide a brief summary of what was changed every time we save a new version of the project. We also get to examine exactly what was modified in the content of the file. As a result, we will be able to see who made what changes to the project.
- Inside the VCS, all the previous variants and versions are properly stored. We will be able to request any version at any moment, and we will be able to retrieve a snapshot of the entire project at our fingertips.
- A VCS that is distributed, such as Git, lets all the team members retrieve a complete history of the project. This allows developers or other stakeholders to use the local Git repositories of any of the teammates even if the main server goes down at any point in time.
18. Describe the branching strategies you have used.
To test our knowledge of the purpose of branching and our experience of branching at a past job, this question is usually asked. Below topics can help in answering this DevOps interview question –
- Release branching – We can clone the develop branch to create a Release branch once it has enough functionality for a release. This branch kicks off the next release cycle, thus no new features can be contributed beyond this point. The things that can be contributed are documentation generation, bug fixing, and other release-related tasks. The release is merged into master and given a version number once it is ready to ship. It should also be merged back into the development branch, which may have evolved since the initial release.
- Feature branching – This branching model maintains all modifications for a specific feature contained within a branch. The branch gets merged into master once the feature has been completely tested and approved by using tests that are automated.
Task branching – In this branching model, every task is implemented in its respective branch. The task key is mentioned in the branch name. We need to simply look at the task key in the branch name to discover which code implements which task.
19. Can you explain the “Shift left to reduce failure” concept in DevOps?
Shift left is a DevOps idea for improving security, performance, and other factors. Let us take an example: if we look at all of the processes in DevOps, we can state that security is tested prior to the deployment step. We can add security in the development phase, which is on the left, by employing the left shift method. [will be depicted in a diagram] We can integrate with all phases, including before development and during testing, not just development. This most likely raises the security level by detecting faults at an early stage.
20. What is the Blue/Green Deployment Pattern?
This is a method of continuous deployment that is commonly used to reduce downtime. This is where traffic is transferred from one instance to another. In order to include a fresh version of code, we must replace the old code with a new code version.
The new version exists in a green environment and the old version exists in a blue environment. After making changes to the previous version, we need a new instance from the old one to execute a newer version of the instance.
21. What is Continuous Testing?
Continuous Testing constitutes the running of automated tests as part of the software delivery pipeline to provide instant feedback on the business risks present in the most recent release. In order to prevent problems in step-switching in the Software delivery life-cycle and to allow Development teams to receive immediate feedback, every build is continually tested in this manner. This results in significant increase in speed in a developer’s productivity as it eliminates the requirement for re-running all the tests after each update and project re-building.
22. What is Automation Testing?
Test automation or manual testing Automation is the process of automating a manual procedure in order to test an application or system. Automation testing entails the use of independent testing tools that allow you to develop test scripts that can be run repeatedly without the need for human interaction.
23. What are the benefits of Automation Testing?
Some of the advantages of Automation Testing are –
- Helps to save money and time.
- Unattended execution can be easily done.
- Huge test matrices can be easily tested.
- Parallel execution is enabled.
- Reduced human-generated errors, which results in improved accuracy.
- Repeated test tasks execution is supported.
24. How to automate Testing in the DevOps lifecycle?
Developers are obliged to commit all source code changes to a shared DevOps repository.
Every time a change is made in the code, Jenkins-like Continuous Integration tools will grab it from this common repository and deploy it for Continuous Testing, which is done by tools like Selenium.
25. Why is Continuous Testing important for DevOps?
Any modification to the code may be tested immediately with Continuous Testing. This prevents concerns like quality issues and release delays that might occur whenever big-bang testing is delayed until the end of the cycle. In this way, Continuous Testing allows for high-quality and more frequent releases.
26. What are the key elements of Continuous Testing tools?
Continuous Testing key elements are:
- Test Optimization – It guarantees that tests produce reliable results and actionable information. Test Data Management, Test Optimization Management, and Test Maintenance are examples of aspects.
- Advanced Analysis – In order to avoid problems from occurring in the first place and to achieve more within each iteration, it employs automation in areas like scope assessment/prioritization, changes effect analysis, and static code analysis.
- Policy Analysis – It guarantees that all processes are in line with the organization’s changing business needs and that all compliance requirements are met.
- Risk Assessment – Test coverage optimization, technical debt, risk mitigation duties, and quality evaluation are all covered to guarantee the build is ready to move on to the next stage.
- Service Virtualization – Ensures that real-world testing scenarios are available. Service visualisation provides access to a virtual representation of the needed testing phases, ensuring its availability and reducing the time spent setting up the test environment.
- Requirements Traceability – It guarantees that no rework is necessary and real criteria are met. To determine which needs require additional validation, are in jeopardy and performing as expected, an object evaluation is used.
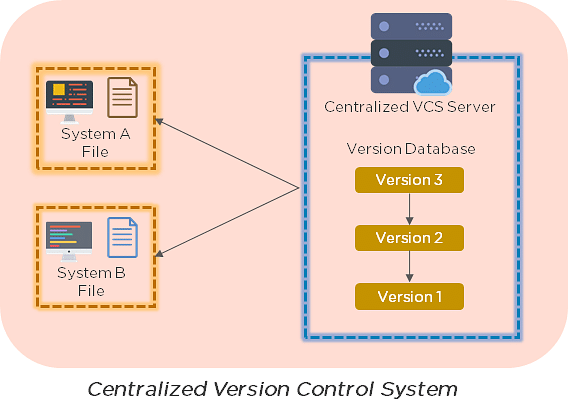
27. Explain the difference between a centralized and distributed version control system (VCS).
Centralized Version Control System
- All file versions are stored on a central server
- No developer has a copy of all files on a local system
- If the central server crashes, all data from the project will be lost
Distributed Control System
- Every developer has a copy of all versions of the code on their systems
- Enables team members to work offline and does not rely on a single location for backups
- There is no threat, even if the server crashes
28. What is the git command that downloads any repository from GitHub to your computer?
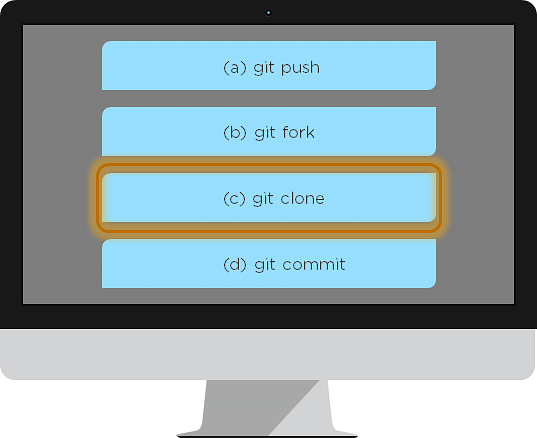
The git command that downloads any repository from GitHub to your computer is git clone.
29. How do you push a file from your local system to the GitHub repository using Git?
First, connect the local repository to your remote repository:
git remote add origin [copied web address]
// Ex: git remote add origin https://github.com/Simplilearn-github/test.git
Second, push your file to the remote repository:
git push origin master
30. How is a bare repository different from the standard way of initializing a Git repository?
Using the standard method:
git init
- You create a working directory with git init
- A .git subfolder is created with all the git-related revision history
Using the bare way
git init –bare
- It does not contain any working or checked out a copy of source files
- Bare repositories store git revision history in the root folder of your repository, instead of the .git subfolder
31. Which of the following CLI commands can be used to rename files?
- git rm
- git mv
- git rm -r
- None of the above
The correct answer is B) git mv
32. What is the process for reverting a commit that has already been pushed and made public?
There are two ways that you can revert a commit:
- Remove or fix the bad file in a new commit and push it to the remote repository. Then commit it to the remote repository using:
git commit –m “commit message” - Create a new commit that undoes all the changes that were made in the bad commit. Use the following command:
git revert <commit id>
Example: git revert 56de0938f
33. Explain the difference between git fetch and git pull.
| Git fetch | Git pull |
| Git fetch only downloads new data from a remote repository | Git pull updates the current HEAD branch with the latest changes from the remote server |
| Does not integrate any new data into your working files | Downloads new data and integrate it with the current working files |
| Users can run a Git fetch at any time to update the remote-tracking branches | Tries to merge remote changes with your local ones |
| Command – git fetch origin git fetch –-all | Command – git pull origin master |
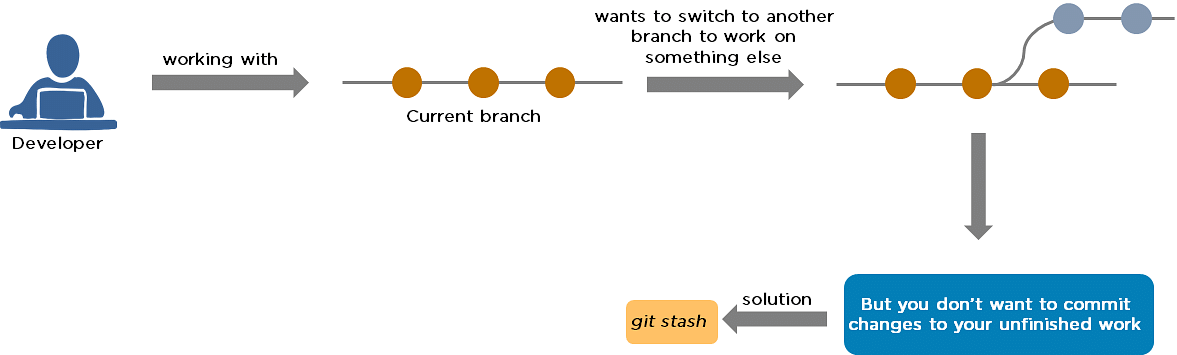
34. What is Git stash?
A developer working with a current branch wants to switch to another branch to work on something else, but the developer doesn’t want to commit changes to your unfinished work. The solution to this issue is Git stash. Git stash takes your modified tracked files and saves them on a stack of unfinished changes that you can reapply at any time.
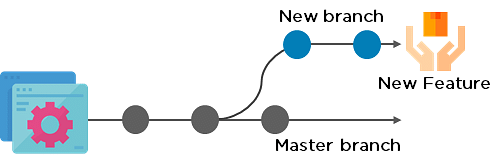
35. Explain the concept of branching in Git.
Suppose you are working on an application, and you want to add a new feature to the app. You can create a new branch and build the new feature on that branch.
- By default, you always work on the master branch
- The circles on the branch represent various commits made on the branch
- After you are done with all the changes, you can merge it with the master branch
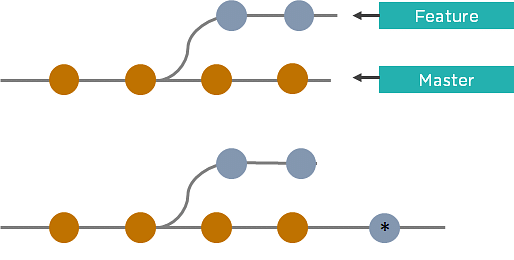
36. What is the difference between Git Merge and Git Rebase?
Suppose you are working on a new feature in a dedicated branch, and another team member updates the master branch with new commits. You can use these two functions:
Git Merge
To incorporate the new commits into your feature branch, use Git merge.
- Creates an extra merge commit every time you need to incorporate changes
- But, it pollutes your feature branch history
Git Rebase
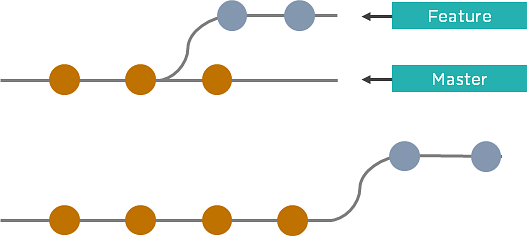
As an alternative to merging, you can rebase the feature branch on to master.
- Incorporates all the new commits in the master branch
- It creates new commits for every commit in the original branch and rewrites project history
37. How do you find a list of files that have been changed in a particular commit?
The command to get a list of files that have been changed in a particular commit is:
git diff-tree –r {commit hash}
Example: git diff-tree –r 87e673f21b
- -r flag instructs the command to list individual files
- commit hash will list all the files that were changed or added in that commit
38. What is a merge conflict in Git, and how can it be resolved?
A Git merge conflict happens when you have merge branches with competing for commits, and Git needs your help to decide which changes to incorporate in the final merge. Manually edit the conflicted file to select the changes that you want to keep in the final merge.
Resolve using GitHub conflict editor
This is done when a merge conflict is caused after competing for line changes. For example, this may occur when people make different changes to the same line of the same file on different branches in your Git repository.
- Resolving a merge conflict using conflict editor:
- Under your repository name, click “Pull requests.”
- In the “Pull requests” drop-down, click the pull request with a merge conflict that you’d like to resolve
- Near the bottom of your pull request, click “Resolve conflicts.”
- Decide if you only want to keep your branch’s changes, the other branch’s changes, or make a brand new change, which may incorporate changes from both branches.
- Delete the conflict markers <<<<<<<, =======, >>>>>>> and make changes you want in the final merge.
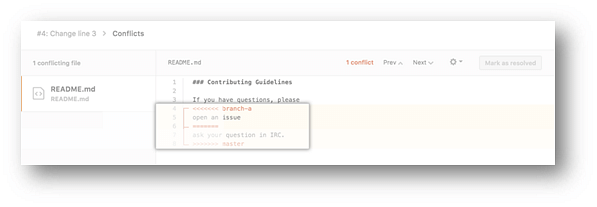
- If you have more than one merge conflict in your file, scroll down to the next set of conflict markers and repeat steps four and five to resolve your merge conflict.
- Once you have resolved all the conflicts in the file, click Mark as resolved.
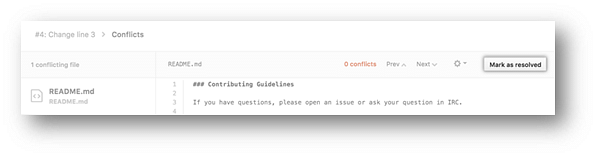
- If you have more than one file with a conflict, select the next file you want to edit on the left side of the page under “conflicting files” and repeat steps four to seven until you’ve resolved all of your pull request’s merge conflicts.
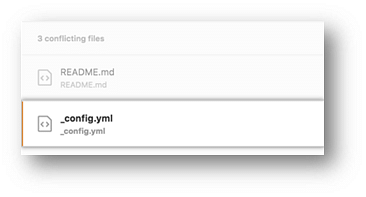
- Once you’ve resolved your merge conflicts, click Commit merge. This merges the entire base branch into your head branch.

- To merge your pull request, click Merge pull request.
- A merge conflict is resolved using the command line.
- Open Git Bash.
- Navigate into the local Git repository that contains the merge conflict.

- Generate a list of the files that the merge conflict affects. In this example, the file styleguide.md has a merge conflict.

- Open any text editor, such as Sublime Text or Atom, and navigate to the file that has merge conflicts.
- To see the beginning of the merge conflict in your file, search the file for the conflict marker “<<<<<<<. ” Open it, and you’ll see the changes from the base branch after the line “<<<<<<< HEAD.”
- Next, you’ll see “=======”, which divides your changes from the changes in the other branch, followed by “>>>>>>> BRANCH-NAME”.

- Decide if you only want to keep your branch’s changes, the other branch’s changes, or make a brand new change, which may incorporate changes from both branches.
- Delete the conflict markers “<<<<<<<“, “=======”, “>>>>>>>” and make the changes you want in the final merge.
In this example, both the changes are incorporated into the final merge:

- Add or stage your changes.

- Commit your changes with a comment.

Now you can merge the branches on the command line, or push your changes to your remote repository on GitHub and merge your changes in a pull request.
39. What is Git bisect? How can you use it to determine the source of a (regression) bug?
Git bisect is a tool that uses binary search to locate the commit that triggered a bug.
Git bisect command –
git bisect;subcommand; options;
The git bisect command is used in finding the bug performing commit in the project by using a binary search algorithm.
The bug occurring commit is called the “bad” commit, and the commit before the bug occurring one is called the “good” commit. We convey the same to the git bisect tool, and it picks a random commit between the two endpoints and prompts whether that one is the “good” or “bad” one. The process continues uptil the range is narrowed down and the exact commit that introduced the exact change is discovered.
40. Explain some basic Git commands.
Some of the Basic Git Commands are summarized in the below table –
| Command | Purpose |
| git init | Used to start a new repository. |
| git config -git config –global user.name “[name]”git config –global user.email “[email address]” | This helps to set the username and email to whom the commits belong to. |
| git clone <repository path> | Used to create a local copy of an existing repository. |
| git add -git add <file names separated by commas>git add . | Used to add one or more files to the staging area. |
| git commit -git commit -a git commit -m “<add commit message>” | Creates a snapshot or records of the file(s) that are in the staging area. |
| git diff -git diff [first branch] [second branch]git diff -staged | Used to show differences between the two mentioned branches/differences made in the files in the staging area vs current version. |
| git status | Lists out all the files that are to be committed. |
| git rm <file name(s)> | Used to delete a file(s) from the current working directory and also stages it. |
| git show <commit> | Shows the content changes and metadata of the mentioned commit. |
| git branch -git branch [branch name]git branch -d [branch name]git branch | The first one creates a brand new branch.The second is used to delete the mentioned branch.The last one lists out all the branches available and also highlights the branch we are in currently. |
41. Explain the master-slave architecture of Jenkins.

- Jenkins master pulls the code from the remote GitHub repository every time there is a code commit.
- It distributes the workload to all the Jenkins slaves.
- On request from the Jenkins master, the slaves carry out, builds, test, and produce test reports.
42. What is Jenkinsfile?
Jenkinsfile contains the definition of a Jenkins pipeline and is checked into the source control repository. It is a text file.
- It allows code review and iteration on the pipeline.
- It permits an audit trail for the pipeline.
- There is a single source of truth for the pipeline, which can be viewed and edited.
43. Which of the following commands runs Jenkins from the command line?
- java –jar Jenkins.war
- java –war Jenkins.jar
- java –jar Jenkins.jar
- java –war Jenkins.war
The correct answer is A) java –jar Jenkins.war
44. What concepts are key aspects of the Jenkins pipeline?
- Pipeline: User-defined model of a CD pipeline. The pipeline’s code defines the entire build process, which includes building, testing and delivering an application
- Node: A machine that is part of the Jenkins environment and capable of executing a pipeline
- Step: A single task that tells Jenkins what to do at a particular point in time
- Stage: Defines a conceptually distinct subset of tasks performed through the entire pipeline (build, test, deploy stages)
45. Which file is used to define dependency in Maven?
- build.xml
- pom.xml
- dependency.xml
- Version.xml
The correct answer is B) pom.xml
46. Explain the two types of pipeline in Jenkins, along with their syntax.
Jenkins provides two ways of developing a pipeline code: Scripted and Declarative. A. Scripted Pipeline: It is based on Groovy script as their Domain Specific Language. One or more node blocks do the core work throughout the entire pipeline.
Syntax:
- Executes the pipeline or any of its stages on any available agent
- Defines the build stage
- Performs steps related to building stage
- Defines the test stage
- Performs steps related to the test stage
- Defines the deploy stage
- Performs steps related to the deploy stage
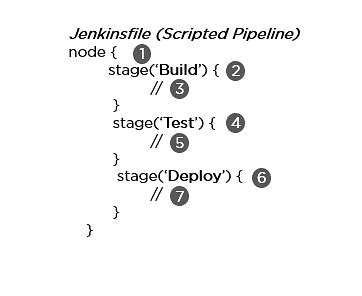
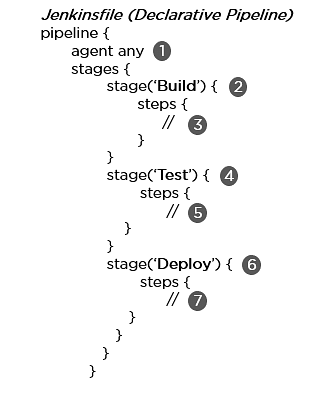
B. Declarative Pipeline: It provides a simple and friendly syntax to define a pipeline. Here, the pipeline block defines the work done throughout the pipeline.
Syntax:
- Executes the pipeline or any of its stages on any available agent
- Defines the build stage
- Performs steps related to building stage
- Defines the test stage
- Performs steps related to the test stage
- Defines the deploy stage
- Performs steps related to the deploy stage
47. How do you create a backup and copy files in Jenkins?
In order to create a backup file, periodically back up your JENKINS_HOME directory.
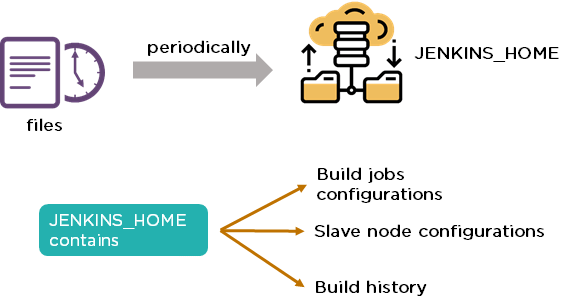
In order to create a backup of Jenkins setup, copy the JENKINS_HOME directory. You can also copy a job directory to clone or replicate a job or rename the directory.
48. How can you copy Jenkins from one server to another?
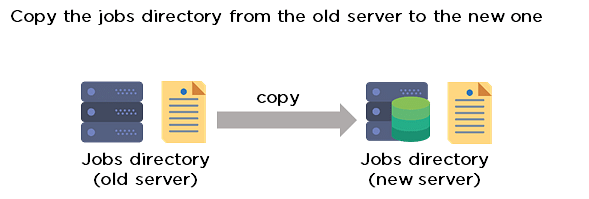
- Move the job from one Jenkins installation to another by copying the corresponding job directory.
- Create a copy of an existing job by making a clone of a job directory with a different name.
- Rename an existing job by renaming a directory.
49. Name three security mechanisms Jenkins uses to authenticate users.
- Jenkins uses an internal database to store user data and credentials.
- Jenkins can use the Lightweight Directory Access Protocol (LDAP) server to authenticate users.
- Jenkins can be configured to employ the authentication mechanism that the deployed application server uses.
50. How is a custom build of a core plugin deployed?
Steps to deploy a custom build of a core plugin:
- Copy the .hpi file to $JENKINS_HOME/plugins
- Remove the plugin’s development directory
- Create an empty file called <plugin>.hpi.pinned
- Restart Jenkins and use your custom build of a core plugin

