
If you are interested to learn about the Python Multitreaded Programming
c regardless of operating system and/or developmental language.
What is XML?
The Extensible Markup Language (XML) is a markup language much like HTML or SGML. This is recommended by the World Wide Web Consortium and available as an open standard. XML is extremely useful for keeping track of small to medium amounts of data without requiring a SQL-based backbone.
Can Python process XML?
The XML tree structure makes navigation, modification, and removal relatively simple programmatically. Python has a built in library, ElementTree, that has functions to read and manipulate XMLs (and other similarly structured files).
How does Python process XML data?
In order to parse XML document you need to have the entire document in memory.
- To parse XML document.
- Import xml.dom.minidom.
- Use the function “parse” to parse the document ( doc=xml.dom.minidom.parse (file name);
- Call the list of XML tags from the XML document using code (=doc.getElementsByTagName( “name of xml tags”)
XML Parser Architectures and APIs
The Python standard library provides a minimal but useful set of interfaces to work with XML. The two most basic and broadly used APIs to XML data are the SAX and DOM interfaces.
- Simple API for XML (SAX) − Here, you register callbacks for events of interest and then let the parser proceed through the document. This is useful when your documents are large or you have memory limitations, it parses the file as it reads it from disk and the entire file is never stored in memory.
- Document Object Model (DOM) API − This is a World Wide Web Consortium recommendation wherein the entire file is read into memory and stored in a hierarchical (tree-based) form to represent all the features of an XML document.
SAX obviously cannot process information as fast as DOM can when working with large files. On the other hand, using DOM exclusively can really kill your resources, especially if used on a lot of small files. SAX is read-only, while DOM allows changes to the XML file. Since these two different APIs literally complement each other, there is no reason why you cannot use them both for large projects. For all our XML code examples, let’s use a simple XML file movies.xml as an input −
<collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>War, Thriller</type> <format>DVD</format> <year>2003</year> <rating>PG</rating> <stars>10</stars> <description>Talk about a US-Japan war</description> </movie> <movie title="Transformers"> <type>Anime, Science Fiction</type> <format>DVD</format> <year>1989</year> <rating>R</rating> <stars>8</stars> <description>A schientific fiction</description> </movie> <movie title="Trigun"> <type>Anime, Action</type> <format>DVD</format> <episodes>4</episodes> <rating>PG</rating> <stars>10</stars> <description>Vash the Stampede!</description> </movie> <movie title="Ishtar"> <type>Comedy</type> <format>VHS</format> <rating>PG</rating> <stars>2</stars> <description>Viewable boredom</description> </movie> </collection>
Parsing XML with SAX APIs
SAX is a standard interface for event-driven XML parsing. Parsing XML with SAX generally requires you to create your own ContentHandler by subclassing xml.sax.ContentHandler. Your ContentHandler handles the particular tags and attributes of your flavor(s) of XML. A ContentHandler object provides methods to handle various parsing events. Its owning parser calls ContentHandler methods as it parses the XML file. The methods startDocument and endDocument are called at the start and the end of the XML file. The method characters(text) is passed character data of the XML file via the parameter text.
The ContentHandler is called at the start and end of each element. If the parser is not in namespace mode, the methods startElement(tag, attributes) and endElement(tag) are called; otherwise, the corresponding methods startElementNS and endElementNS are called. Here, tag is the element tag, and attributes is an Attributes object. Here are other important methods to understand before proceeding −
The make_parser Method
Following method creates a new parser object and returns it. The parser object created will be of the first parser type the system finds.
xml.sax.make_parser( [parser_list] )
Here is the detail of the parameters −
- parser_list − The optional argument consisting of a list of parsers to use which must all implement the make_parser method.
The parse Method
Following method creates a SAX parser and uses it to parse a document.
xml.sax.parse( xmlfile, contenthandler[, errorhandler])
Here is the detail of the parameters −
- xmlfile − This is the name of the XML file to read from.
- contenthandler − This must be a ContentHandler object.
- errorhandler − If specified, errorhandler must be a SAX ErrorHandler object.
The parseString Method
There is one more method to create a SAX parser and to parse the specified XML string.
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])
Here is the detail of the parameters −
- xmlstring − This is the name of the XML string to read from.
- contenthandler − This must be a ContentHandler object.
- errorhandler − If specified, errorhandler must be a SAX ErrorHandler object.
Example
#!/usr/bin/python
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# Call when an element starts
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print "*****Movie*****"
title = attributes["title"]
print "Title:", title
# Call when an elements ends
def endElement(self, tag):
if self.CurrentData == "type":
print "Type:", self.type
elif self.CurrentData == "format":
print "Format:", self.format
elif self.CurrentData == "year":
print "Year:", self.year
elif self.CurrentData == "rating":
print "Rating:", self.rating
elif self.CurrentData == "stars":
print "Stars:", self.stars
elif self.CurrentData == "description":
print "Description:", self.description
self.CurrentData = ""
# Call when a character is read
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# override the default ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")This would produce following result −
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Stars: 10
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Stars: 2
Description: Viewable boredom
For a complete detail on SAX API documentation, please refer to standard Python SAX APIs.
Parsing XML with DOM APIs
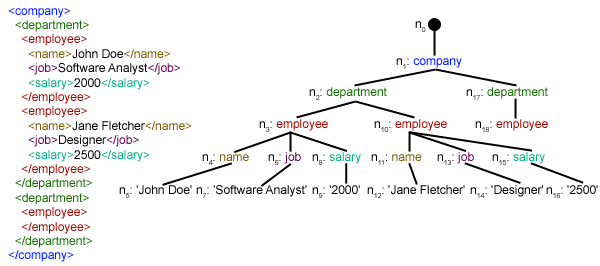
The Document Object Model (“DOM”) is a cross-language API from the World Wide Web Consortium (W3C) for accessing and modifying XML documents. The DOM is extremely useful for random-access applications. SAX only allows you a view of one bit of the document at a time. If you are looking at one SAX element, you have no access to another. Here is the easiest way to quickly load an XML document and to create a minidom object using the xml.dom module. The minidom object provides a simple parser method that quickly creates a DOM tree from the XML file. The sample phrase calls the parse( file [,parser] ) function of the minidom object to parse the XML file designated by file into a DOM tree object.
#!/usr/bin/python
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document using minidom parser
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print "Root element : %s" % collection.getAttribute("shelf")
# Get all the movies in the collection
movies = collection.getElementsByTagName("movie")
# Print detail of each movie.
for movie in movies:
print "*****Movie*****"
if movie.hasAttribute("title"):
print "Title: %s" % movie.getAttribute("title")
type = movie.getElementsByTagName('type')[0]
print "Type: %s" % type.childNodes[0].data
format = movie.getElementsByTagName('format')[0]
print "Format: %s" % format.childNodes[0].data
rating = movie.getElementsByTagName('rating')[0]
print "Rating: %s" % rating.childNodes[0].data
description = movie.getElementsByTagName('description')[0]
print "Description: %s" % description.childNodes[0].dataThis would produce the following result −
Root element : New Arrivals
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Rating: PG
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Rating: R
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Description: Viewable boredomIntroduction to ElementTree
The XML tree structure makes navigation, modification, and removal relatively simple programmatically. Python has a built in library, ElementTree, that has functions to read and manipulate XMLs (and other similarly structured files).
First, import ElementTree. It’s a common practice to use the alias of ET:
import xml.etree.ElementTree as ET
Parsing XML Data
In the XML file provided, there is a basic collection of movies described. The only problem is the data is a mess! There have been a lot of different curators of this collection and everyone has their own way of entering data into the file. The main goal in this tutorial will be to read and understand the file with Python — then fix the problems. First you need to read in the file with ElementTree.
<strong>tree = ET.parse('movies.xml')<br></strong><mark><strong>root = tree.getroot()</strong></mark>Now that you have initialized the tree, you should look at the XML and print out values in order to understand how the tree is structured.
<strong>root.tag</strong>'collection'
At the top level, you see that this XML is rooted in the collection tag.
<strong>root.attrib</strong>{}For Loops
You can easily iterate over subelements (commonly called “children”) in the root by using a simple “for” loop.
<strong>for child in root:<br> print(child.tag, child.attrib)</strong>genre {'category': 'Action'}<br>genre {'category': 'Thriller'}<br>genre {'category': 'Comedy'}Now you know that the children of the root collection are all genre. To designate the genre, the XML uses the attribute category. There are Action, Thriller, and Comedy movies according the genre element. Typically it is helpful to know all the elements in the entire tree. One useful function for doing that is root.iter().
<strong>[elem.tag for elem in root.iter()]</strong>['collection',<br> 'genre',<br> 'decade',<br> 'movie',<br> 'format',<br> 'year',<br> 'rating',<br> 'description',<br> 'movie',<br> .<br> .<br> .<br> .<br> 'movie',<br> 'format',<br> 'year',<br> 'rating',<br> 'description']
There is a helpful way to see the whole document. If you pass the root into the .tostring() method, you can return the whole document. Within ElementTree, this method takes a slightly strange form. Since ElementTree is a powerful library that can interpret more than just XML, you must specify both the encoding and decoding of the document you are displaying as the string. You can expand the use of the iter() function to help with finding particular elements of interest. root.iter() will list all subelements under the root that match the element specified. Here, you will list all attributes of the movie element in the tree:
<strong>for movie in root.iter('movie'):<br>
print(movie.attrib)</strong>{'favorite': 'True', 'title':
'Indiana Jones: The raiders of the lost Ark'}<br>{'favorite': 'True',
'title': 'THE KARATE KID'}<br>{'favorite': 'False', 'title':
'Back 2 the Future'}<br>{'favorite': 'False', 'title': 'X-Men'}<br>{'favorite': 'True', 'title': 'Batman Returns'}<br>{'favorite': 'False', 'title':
'Reservoir Dogs'}<br>{'favorite': 'False', 'title': 'ALIEN'}<br>{'favorite':
'True', 'title': "Ferris Bueller's Day Off"}<br>{'favorite': 'FALSE', 'title': '
American Psycho'}<br>{'favorite': 'False', 'title': 'Batman: The Movie'}<br>{'favorite': 'True', 'title': 'Easy A'}<br>{'favorite': 'True', 'title': 'Dinner for SCHMUCKS'}<br>{'favorite':
'False', 'title': 'Ghostbusters'}<br>{'favorite': 'True', 'title': 'Robin Hood: Prince of Thieves'}XPath Expressions
Many times elements will not have attributes, they will only have text content. Using the attribute .text, you can print out this content. Now, print out all the descriptions of the movies.
<strong>for description in root.iter('description'):<br>
print(description.text)</strong>'Archaeologist and adventurer Indiana Jones is hired by the U.S. government to find the Ark of the Covenant before the Nazis.'None provided.
<br>Marty McFly<br>Two mutants come to a private academy for their kind whose resident superhero team must oppose a terrorist organization with similar powers.
<br>NA.<br>WhAtEvER I Want!!!?!<br>"""""""""<br>Funny movie about a funny guy<br>psychopathic Bateman<br>What a joke!<br>Emma Stone = Hester Prynne<br>Tim (Rudd) is a rising executive who “succeeds” in finding the perfect guest, IRS employee Barry (Carell), for his boss’ monthly event, a so-called “dinner for idiots,
” which offers certain <br>advantages to the exec who shows up with the biggest buffoon.Who ya gonna call?<br>Robin Hood slayingPrinting out the XML is helpful, but XPath is a query language used to search through an XML quickly and easily. However, Understanding XPath is critically important to scanning and populating XMLs. ElementTree has a .findall() function that will traverse the immediate children of the referenced element. Here, you will search the tree for movies that came out in 1992:
<strong>for movie in root.findall("./genre/decade/movie/[year='1992']"):
<br> print(movie.attrib)</strong>{'favorite'
: 'True', 'title': 'Batman Returns'}<br>{'favorite': 'False', 'title': 'Reservoir Dogs'}The function .findall() always begins at the element specified. This type of function is extremely powerful for a “find and replace”. You can even search on attributes! Now, print out only the movies that are available in multiple formats (an attribute).
<strong>for movie in root.findall("./genre/decade/movie/format/[@multiple='Yes']"):
<br> print(movie.attrib)</strong>{'multiple': 'Yes'}<br>{'multiple':
'Yes'}<br>{'multiple': 'Yes'}<br>{'multiple': 'Yes'}<br>{'multiple': 'Yes'}Brainstorm why, in this case, the print statement returns the “Yes” values of multiple. Think about how the “for” loop is defined.
Tip: use '...' inside of XPath to return the parent element of the current element.
<strong>for movie in root.findall("./genre/decade/movie/format[@multiple='Yes']..."):<br>
print(movie.attrib)</strong>{'favorite': 'True', 'title': 'THE KARATE KID'}<br>{'favorite':
'False', 'title': 'X-Men'}<br>{'favorite': 'False', 'title': 'ALIEN'}<br>{'favorite': 'False', 'title':
'Batman: The Movie'}<br>{'favorite': 'True', 'title': 'Dinner for SCHMUCKS'}Modifying an XML
Earlier, the movie titles were an absolute mess. Now, print them out again:
<strong>for movie in root.iter('movie'):<br> print(movie.attrib)</strong>{'favorite': 'True', 'title':
'Indiana Jones: The raiders of the lost Ark'}<br>{'favorite': 'True', 'title': 'THE KARATE KID'}<br>{'favorite': 'False', 'title': 'Back 2 the Future'}<br>{'favorite': 'False', 'title': 'X-Men'}<br>{'favorite':
'True', 'title': 'Batman Returns'}<br>{'favorite': 'False', 'title': 'Reservoir Dogs'}
<br>{'favorite': 'False', 'title': 'ALIEN'}<br>{'favorite': 'True', 'title': "Ferris Bueller's Day Off"}<br>{'favorite':
'FALSE', 'title': 'American Psycho'}<br>{'favorite': 'False', 'title': 'Batman: The Movie'}
<br>{'favorite': 'True', 'title': 'Easy A'}<br>{'favorite': 'True', 'title': 'Dinner for SCHMUCKS'}<br>{'favorite':
'False', 'title': 'Ghostbusters'}<br>{'favorite': 'True', 'title': 'Robin Hood: Prince of Thieves'}Fix the ‘2’ in Back 2 the Future. That should be a find and replace problem. Write code to find the title ‘Back 2 the Future’ and save it as a variable:
<strong>b2tf = root.find("./genre/decade/movie[@title='Back 2 the Future']")
<br>print(b2tf)</strong><Element 'movie' at 0x10ce00ef8>Notice that using the .find() method returns an element of the tree. Much of the time, it is more useful to edit the content within an element. Modify the title attribute of the Back 2 the Future element variable to read “Back to the Future”. Then, print out the attributes of your variable to see your change. You can easily do this by accessing the attribute of an element and then assigning a new value to it:
<strong>b2tf.attrib["title"] = "Back to the Future"<br>print(b2tf.attrib)</strong>
{'favorite': 'False', 'title': 'Back to the Future'}Write out your changes back to the XML so they are permanently fixed in the document. Print out your movie attributes again to make sure your changes worked. Use the .write() method to do this:
<strong>tree.write("movies.xml")</strong><strong>tree = ET.parse('movies.xml')<br>root = tree.getroot()</strong><strong>for movie in root.iter('movie'):<br> print(movie.attrib)</strong>{'favorite': 'True', 'title': 'Indiana Jones:
The raiders of the lost Ark'}<br>{'favorite':
'True', 'title': 'THE KARATE KID'}<br>{'favorite': 'False', 'title':
'Back to the Future'}<br>{'favorite': 'False', 'title': 'X-Men'}<br>{'favorite': 'True', 'title':
'Batman Returns'}<br>{'favorite': 'False', 'title':
'Reservoir Dogs'}<br>{'favorite': 'False', 'title':
'ALIEN'}<br>{'favorite': 'True', 'title': "Ferris Bueller's Day Off"}<br>{'favorite':
'FALSE', 'title': 'American Psycho'}<br>{'favorite':
'False', 'title': 'Batman: The Movie'}<br>{'favorite':
'True', 'title': 'Easy A'}<br>{'favorite': 'True', 'title':
'Dinner for SCHMUCKS'}<br>{'favorite': 'False', 'title':
'Ghostbusters'}<br>{'favorite': 'True', 'title': 'Robin Hood: Prince of Thieves'}Fixing Attributes
The multiple attribute is incorrect in some places. Use ElementTree to fix the designator based on how many formats the movie comes in. First, print the formatattribute and text to see which parts need to be fixed.
<strong>for form in root.findall("./genre/decade/movie/format"):
<br> print(form.attrib, form.text)</strong>{'multiple': 'No'}
DVD<br>{'multiple': 'Yes'} DVD,Online<br>{'multiple': 'False'} Blu-ray<br>{'multiple': 'Yes'}
dvd, digital<br>{'multiple':
'No'} VHS<br>{'multiple': 'No'} Online<br>{'multiple': 'Yes'} DVD<br>{'multiple': 'No'}
DVD<br>{'multiple': 'No'} blue-ray<br>{'multiple': 'Yes'} DVD,VHS<br>{'multiple': 'No'}
DVD<br>{'multiple': 'Yes'} DVD,digital,Netflix<br>{'multiple': 'No'} Online,VHS<br>{'multiple': 'No'} Blu_RayThere is some work that needs to be done on this tag. You can use regex to find commas — that will tell whether the multiple attribute should be “Yes” or “No”. Adding and modifying attributes can be done easily with the .set()method.
<strong>import re</strong><strong>for form in root.findall("./genre/decade/movie/format"):
<br> # Search for the commas in the format text<br> match = re.search(',',form.text)<br> if match:<br> form.set('multiple','Yes')<br> else:
<br> form.set('multiple','No')</strong><strong># Write out the tree to the file again<br>tree.write("movies.xml")</strong><strong>tree = ET.parse('movies.xml')<br>root = tree.getroot()</strong><strong>for form in root.findall("./genre/decade/movie/format"):<br> print(form.attrib, form.text)</strong>{'multiple': 'No'} DVD<br>{'multiple': 'Yes'} DVD,Online<br>{'multiple': 'No'} Blu-ray<br>{'multiple': 'Yes'} dvd, digital<br>{'multiple': 'No'} VHS<br>{'multiple': 'No'} Online<br>{'multiple'
: 'No'} DVD<br>{'multiple': 'No'} DVD<br>{'multiple': 'No'} blue-ray<br>{'multiple': 'Yes'} DVD,VHS<br>{'multiple': 'No'} DVD<br>{'multiple': 'Yes'} DVD,digital,Netflix<br>{'multiple': 'Yes'}
Online,VHS<br>{'multiple': 'No'} Blu_RayMoving Elements
Some of the data has been placed in the wrong decade. Use what you have learned about XML and ElementTree to find and fix the decade data errors. It will be useful to print out both the decade tags and the year tags throughout the document.
<strong>for decade in root.findall("./genre/decade"):
<br> print(decade.attrib)<br> for year in decade.findall("./movie/year"):<br> print(year.text)</strong>{'years': '1980s'}<br>1981 <br>1984 <br>1985 <br>{'years':
'1990s'}<br>2000 <br>1992 <br>1992 <br>{'years': '1970s'}<br>1979 <br>{'years':
'1980s'}<br>1986 <br>2000 <br>{'years': '1960s'}<br>1966 <br>{'years': '2010s'}<br>2010 <br>2011 <br>{'years': '1980s'}<br>1984 <br>{'years': '1990s'}<br>1991The two years that are in the wrong decade are the movies from the 2000s. Figure out what those movies are, using an XPath expression.
<strong>for movie in root.findall("./genre/decade/movie/[year='2000']"):
<br> print(movie.attrib)</strong>{'favorite': 'False', 'title': 'X-Men'}<br>{'favorite': 'FALSE', 'title': 'American Psycho'}You have to add a new decade tag, the 2000s, to the Action genre in order to move the X-Men data. The .SubElement() method can be used to add this tag to the end of the XML.
<strong>action = root.find("./genre[@category='Action']")<br>new_dec = ET.SubElement
(action, 'decade')<br>new_dec.attrib["years"] = '2000s'</strong>Now append the X-Men movie to the 2000s and remove it from the 1990s, using .append() and .remove(), respectively.
<strong>xmen = root.find("./genre/decade/movie[@title='X-Men']")<br>dec2000s = root.find("./genre[@category='Action']/decade[@years='2000s']")<br>dec2000s.append(xmen)<br>dec1990s = root.find("./genre[@category='Action']/decade[@years='1990s']")<br>dec1990s.remove(xmen)</strong>Build XML Documents
Nice, so you were able to essentially move an entire movie to a new decade. Save your changes back to the XML.
<strong>tree.write("movies.xml")</strong><strong>tree = ET.parse('movies.xml')
<br>root = tree.getroot()</strong><strong>print(ET.tostring(root, encoding='utf8').decode('utf8'))</strong>
